
Building a shared memory IPC implementation – Part II

Memory management
This post is a follow-up on Building a shared memory IPC implementation – Part I. I’d like to discuss the way shared memory is handled and allocated for the inter-process queue.
As in all memory management systems, I try to minimize wasted memory on bookkeeping and the number of shared memory allocations, as they might be slow.
For the shared memory IPC queue I opted for the paged memory allocation scheme sketched below:
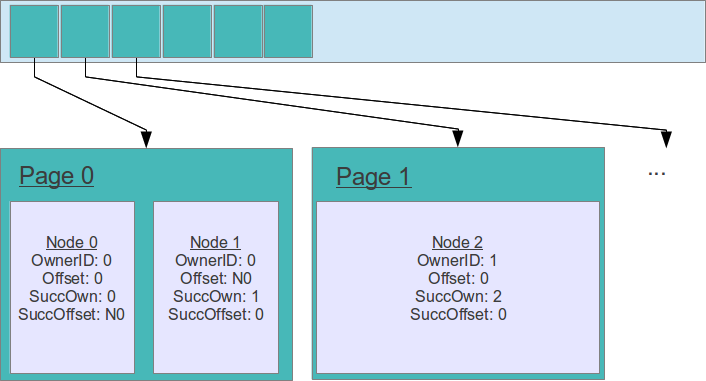
Pages are the ones that get requested form the OS as shared memory regions. For the sake of simplicity and performance they are a fixed number. This incurs a usage limitation as the queue can run out of memory but simplifies the synchronization and management mechanism. The limit should be set reasonably high and reaching it usually means a more serious problem occurred, for instance the consumer stopped working or is too slow.
As you can see on the picture, all shared page handles are put in an array. Only the used pages are requested from the OS – if 3 pages are used from a maximum of 16, then only they will be allocated.
Nodes (messages) are always allocated in one page. If there is not enough room left in a page to accommodate a node, a new page is requested with size = max(newNodeSize*2, DEFAULT_PAGE_SIZE). This formula ensures that pages are never smaller than a preset minimal limit and also allows to have huge nodes. Pages are of variable size which is very handy.
The pair (OwnerID, Offset) uniquely identifies a node.
NB: The identifier of the node is a pair of values and usually it can’t be atomically updated. Special care should be taken to ensure that operator= (assignment) and operator!= are atomic to each other as specified in Building a shared memory IPC implementation – Part I.
A node in the queue knows it’s position but also has the coordinates of it’s successor.
If a node grows up too much and has to expand, but there is not enough room in the page, it is moved to another free one and holes remain. Node allocation goes always forward, there is no attempt to squeeze nodes in empty spaces. Node de-allocation goes always forward too (it’s a queue) so free space will be effectively reclaimed as the node just before it is reclaimed:
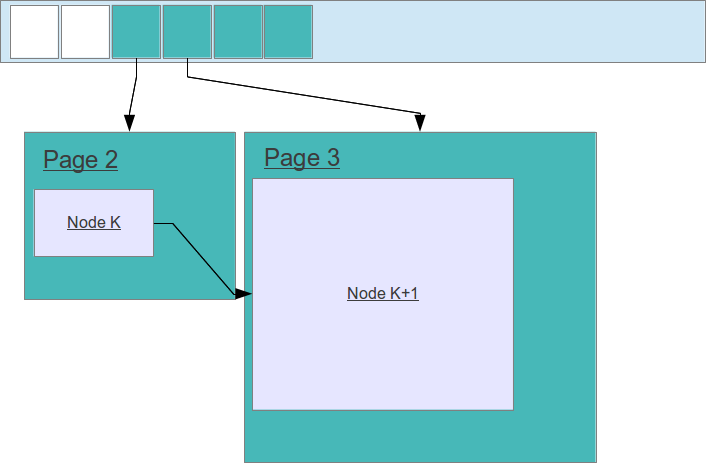
As soon as Node K is freed, the whole Page 2 will be marked as free.
I never return the allocated memory to the OS. When a page is left empty, it is added to a collection of free pages and reused as soon as a new page is required. In my typical usage the pattern is very predictable and stable and just marking a page as reusable allows us to skip costly OS calls when consumption oscillates between M and M+1 pages. If memory is tight or usage spikes are expected, you could free the pages and then reallocated them from the OS.
As pages are freed and reused, nodes will have successors in pages that are not directly next to them. This is not a problem with the described addressing scheme.
When a new node is requested I first check if there is enough room in the current tail’s owner, if not – call AllocateFirstNodeInPage(size_t size):
The method reclaims all pages that are now left empty, checks empty pages for enough size to accommodate the node and as a last resort allocates a new one from the OS.The NodesOwned field of a page is incremented/decremented with atomic operations.
New pages are always allocated by the producer. The consumer also has the same vector of pages but just maps the already allocated memory when it reaches a node in a not-yet-mapped page.
Follow Stoyan on Twitter: @stoyannk